-
안녕하세요.
공상 개발입니다.
지난 시간에 이어 트리(Tree)에 대해 마저 알아보는 시간을 갖겠습니다.

1. 이진 탐색 트리
2. 탐색 연산
-구현 방법
3. 삽입 연산
4. 삭제 연산
5. 성능 분석
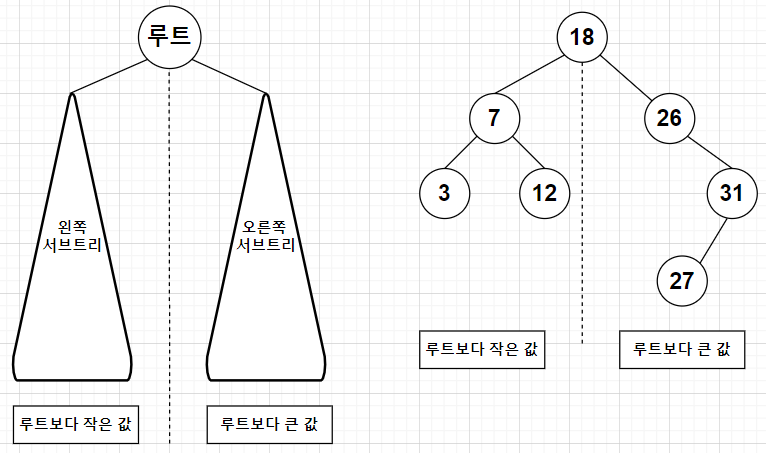
# 이진 탐색 트리 이진 탐색 트리(binary search tree)는 탐색 작업을 효율적으로 하기 위한 자료구조입니다.
key(왼쪽서브트리) ≤ key(루트노드) ≤ key(오른쪽서브트리) 구조입니다.위의 수식을 말로 풀어 본다면,
"왼쪽 서브 트리의 키들은 루트의 키보다 작으며, 오른쪽 서브 트리의 키들은 루트의 키보다 크다"입니다.
이진 탐색 트리의 정의를 보여주는 이미지로 예시를 확인해보겠습니다.
또한 이진 탐색를 중위 순회하면 오름차순으로 정렬된 값을 얻을 수 있습니다.# 탐색 연산 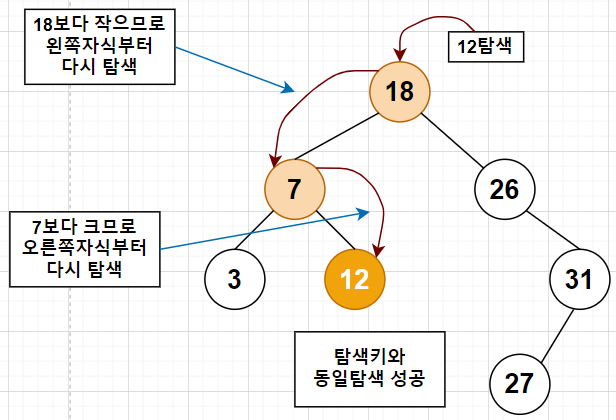
탐색 연산은 보통 순환적인 방법으로 구현하며, 3가지 조건을 통해 동작합니다.
1. 주어진 키값과 루트 노드 값을 비교한 결과가 같으면 탐색을 마친다.
2. 주어진 키값이 루트 노드의 키값보다 작으면 탐색은 이 루트 노드의 왼쪽 자식을 기준으로 다시 시작한다.
3. 주어진 키값이 루트 노드의 키값보다 크면 탐색은 이 루트 노드의 오른쪽 자식을 기준으로 다시 시작한다.다시 시작한다는 말은, 동일한 조건으로 탐색을 시작하겠다는 의미입니다.
동일한 조건을 적용한다는 의미에서는 탐색 연산은 순환적으로 구현할 수 있음을 우리는 알 수 있습니다.
# 구현 방법 탐색 연산을 구현하는 방법에는 2가지가 있습니다.
반복적 방법과 순환적 방법입니다.
보통 순환적 방법으로 구현을 하나, 반복적 방법으로도 구현을 할 수 있습니다.
위에서 언급했던 3가지 조건을 소스 코드로 구현한 이미지입니다.
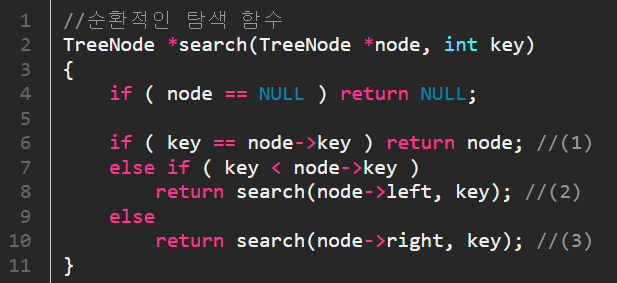
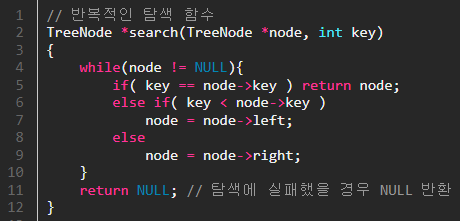
좌측 순환적 방법, 우측 반복적 방법 # 삽입 연산 이진 탐색 트리에 원소를 삽입하기 위해서는 먼저 탐색을 수행하는 것이 필요합니다.
탐색에 실패한 위치가 바로 새로운 노드를 삽입하는 위치입니다.
노드가 없으니 NULL 값이 나오고, 그렇기 때문에 삽입할 수 있는 것이죠.

1. 9를 삽입하기 위해 9가 있나 탐색을 해봅니다.
2. 루트 키인 18보다 작음으로 왼쪽 서브 트리로 이동해 순환적인 방법으로 탐색 연산이 다시 이루어집니다.
3. 그렇다면 루트 키인 7보다 9가 더 크니까 오른쪽 서브 트리로 이동.
4. 새로운 루트 키인 12보다 9는 작으니까 왼쪽 서브 트리로 이동해서 탐색을 하는데 NULL이므로, 삽입이 이루어집니다.
총 3번의 순환이 이루어집니다.
탐색 연산에서 삽입 코드만 추가시켜주면 됩니다.

삽입 연산 # 삭제 연산 삭제 연산입니다.
이진 탐색 트리 관련 알고리즘 중 가장 복잡하지만, 천천히 이미지와 비교해보면서 동작을 이해하시면 괜찮습니다.
삭제 연산의 경우 3가지 케이스가 있습니다.
1. 삭제하려는 노드가 단말 노드일 경우
2. 삭제하려는 노드가 하나의 왼쪽이나 오른쪽 서브 트리 중 하나만 가지고 있는 경우
3. 삭제하려는 노드가 두 개의 서브 트리 모두 가지고 있는 경우
개념을 정리하기 위해 위의 3가지 케이스를 만족하는 이미지를 예시로 확인해보겠습니다.
CASE 1: 삭제하려는 노드가 단말 노드일 경우
-> 단말노드의 부모노드를 찾아서 연결을 끊으면 됨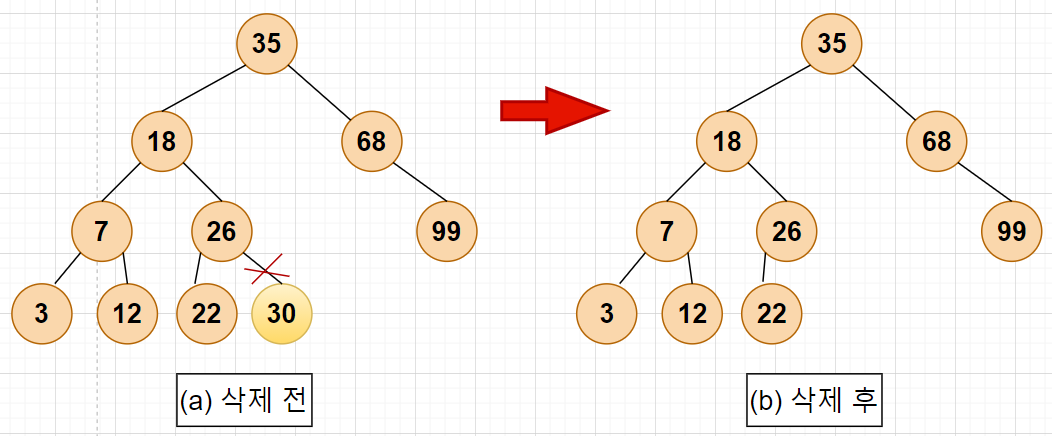
CASE 2: 삭제하려는 노드가 하나의 서브트리만 갖고 있는 경우
-> 그 노드는 삭제하고 서브 트리는 부모 노드에 붙여줌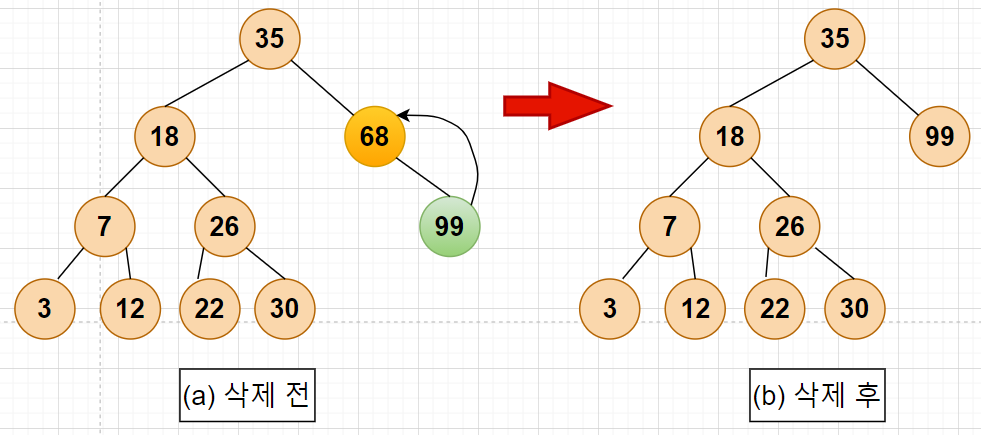
CASE 3: 삭제하려는 노드가 두 개의 서브트리를 갖고 있는 경우
-> 삭제노드와 가장 비슷한 값을 가진 노드를 삭제노드 위치로 변경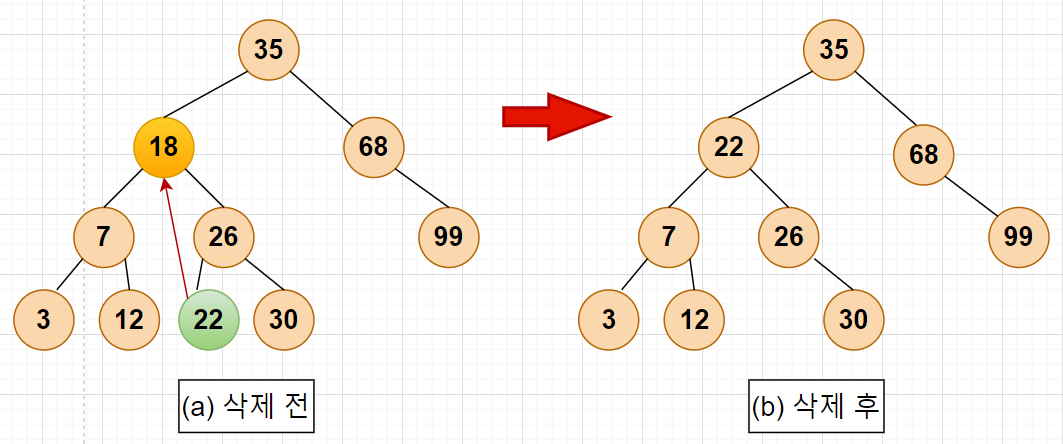
CASE 3 로직 : 가장 비슷한 값은 어디에 있을까? 노드가 두 개의 서브 트리를 모두 가지고 있는 경우, 삭제 노드를 가장 비슷한 값을 가진 노드와 위치를 변경해 줍니다.
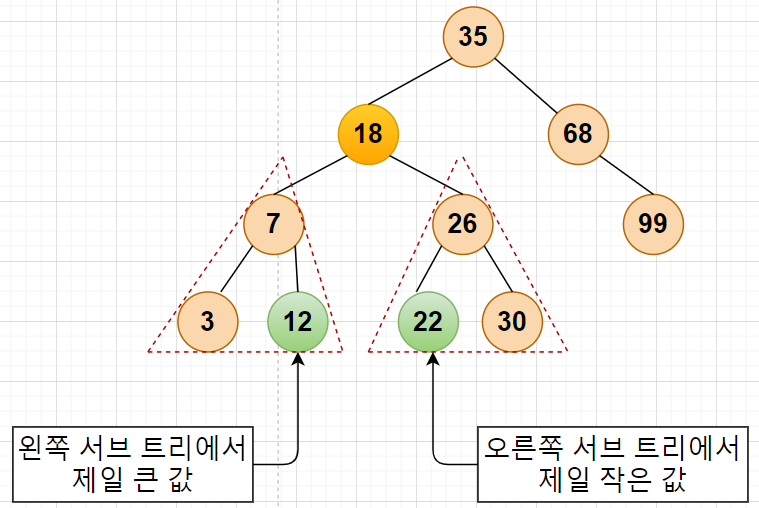
case 3 로직 1. 가장 비슷한 값을 찾아서
2. 위치를 변경(복사) 해주고
3. 삭제 노드를 삭제 연산한다.
case 1, 2, 3을 한 번에 소스코드로 구현해 봅시다.
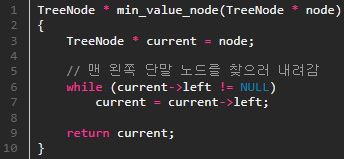

좌측 : 가장 작은 값을 탐색하는 코드, 우측 : 삭제 연산 코드 # 삭제 연산 case 3에 관한 나의 생각 아마 이진 탐색 트리에 관해서 공부를 좀 해보신 분이라면 느끼실 텐데, 삭제 연산에서 왜 오른쪽 서브 트리를
루트키 값과 가장 비슷하다고 가정을 하고 코드를 작성하나 궁금하실 것입니다.
찾아본 결과, "구현하는 사람 마음이다"라는 의견이 제일 많았습니다.
또한 설명하기 쉬운 가정을 예시로 들다 보니까 이런 결과가 나온 거라 생각합니다.
저는 삭제 연산을 처음 접했을 때 이런 식으로 로직을 생각했지만,
1. 왼쪽 서브 트리의 오른쪽 값을 구한다.
2. 오른쪽 서브 트리의 왼쪽 값을 구한다.
3. 루트 키와 각각의 값을 빼본다.
4. 가장 작은 값을 나온 값을 선택한다.왼쪽 서브 트리를 먼저 건드리면 완전 이진 트리가 아니게 되니까 트리의 변동성이 커진다는 의견도 있었습니다.
그렇다면 제가 생각한 최종 결정은 뭔가 걸린다면 max_vaule_node 함수를 하나 더 만들면 된다고 생각합니다.
이와 관련해 정확한 지적이나, 다른 생각을 가지신 분은 아래의 인스타그램 주소로 연락 바랍니다.
확인 후 수정하겠습니다.
# 성능 분석 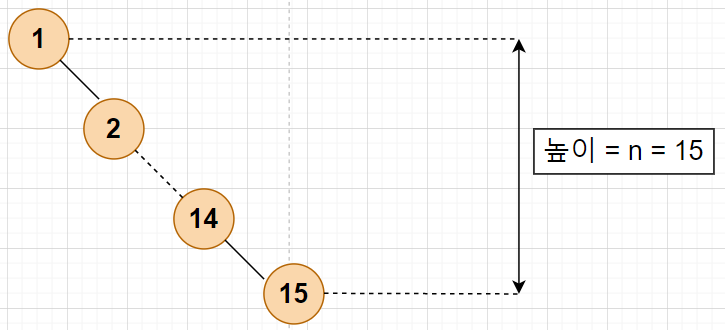
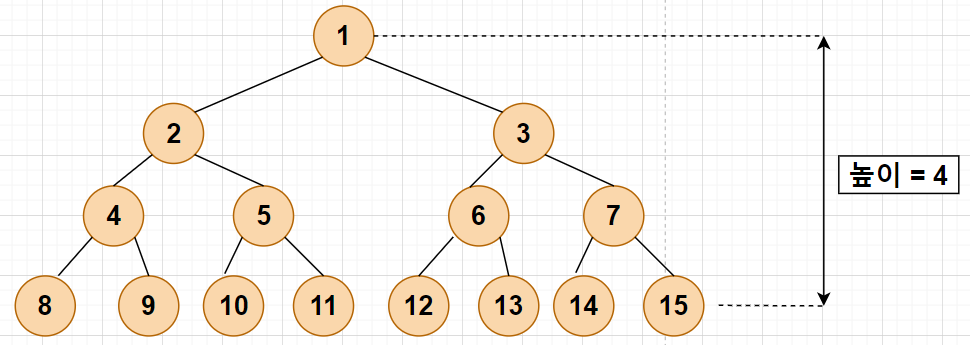
이진 탐색 트리에서의 탐색, 삽입, 삭제 연산의 시간 복잡도는 트리의 높이 h에 비례합니다.
최선의 경우,
이진 트리가 균형적으로 생성되어 있는 경우
h=log2n
최악의 경우,
한쪽으로 치우친 경사 이진 트리의 경우 h=n
순차 탐색과 시간 복잡도가 같습니다.

피드백 작성된 내용 중 잘못된 정보나 접근이 있을 시, www.instagram.com/hong_.98/을 통해 말씀해 주시면 감사하겠습니다.
읽어주셔서 감사합니다.
'Computer Science > Data Structure' 카테고리의 다른 글
Graph - DFS(Depth First Search) 구현 (0) 2021.05.24 Data Structure - 우선순위 큐(priority queue), 힙(heap) (0) 2021.03.02 Data Structure - Tree(Vol.1), (자료구조-트리) (0) 2021.02.23 Data Structure - linked list(Vol.2), (자료 구조-연결 리스트) (0) 2021.02.18 Data Structure - linked list(Vol.1), (자료 구조-연결 리스트) (0) 2021.02.17 댓글
공상개발
상상 박스